HTTP Header i SEO. Co trzeba wiedzieć?


Osiągnięcie wysokich pozycji w wyszukiwarkach internetowych stanowi od kilku lat jedną z wiodących form reklamy internetowej. Im wyżej nasza strona będzie znajdować się pod dane zapytanie, tym większa szansa na pozyskanie użytkowników i konwersję. Niestety, proces pozycjonowania stron z roku na rok stanowi dla pozycjonerów coraz większe wyzwanie, a każdy szczegół może determinować sukces w wyszukiwarkach internetowych.
Techniczne SEO to podstawa, jeżeli chcemy osiągnąć lepsze wyniki niż konkurencja. Niestety, nie zawsze zalecenia z audytu SEO są realne do wprowadzenia. Przeszkodą może być na przykład rodzaj systemu CMS czy ograniczony dostęp do plików źródłowych. Wyobraźmy sobie sytuację: potrzebujemy nadać tag kanoniczny lub noindex,nofollow dla adresów URL, które nie powinny się indeksować (mogą to być przykładowo filtry czy parametry sortowania), natomiast modyfikacje w kodzie nam to utrudniają. W tej sytuacji z pomocą przychodzi nagłówek HTTP wraz ze zwracanymi informacjami.
Nagłówki HTTP zawierają dodatkowe informacja, które są przesyłane pomiędzy komputerem użytkownika a serwerem. Dokładniej, będzie to przesyłanie informacji na przykład pomiędzy przeglądarką a stroną internetową. Nagłówki HTTP zwracają następujące dyrektywy:
HTTP Referer – dyrektywa zwracająca informację o adresie odsyłającym (w analityce wykorzystywana do określania źródła wizyt)
USER Agent – aplikacja określająca lokalizację, z której nastąpiło odwołanie do urządzenia (np. Googlebot)
X-Robots-Tag – informacja dla robotów wyszukiwarek o zasobach, które mają być indeksowalne, a które nie
Server – informacja na temat serwera (np. Apatche)
Cache-control – informacja zawierająca dane opisujące zasoby zapisywane w pamięci podręcznej (często wykorzystywane do optymalizacji pod Core Web Vitals).
O zastosowaniu nagłówków HTTP oraz zwracanych przez nie informacji można wymieniać bardzo dużo przykładów. Natomiast w tym artykule przyjrzymy się zastosowaniu, które może wspomóc proces technicznego SEO i całej optymalizacji. W tym przypadku warto wziąć pod uwagę dyrektywę X-Robots-Tag oraz Server.
Pomimo tego, że informacje uzyskane z dyrektywy Server nie są zbyt skomplikowane czy rozbudowane, to jednak mocno wpływają na przebieg dalszych działań optymalizacyjnych. Dokładniej mówiąc – określi nam typ serwera, ponieważ inaczej będzie wyglądać optymalizacja na serwerach Apache, inaczej na Nginx, a jeszcze inaczej na innym typie serwera. Dzięki temu będziemy wiedzieli na przykład, z jaką dokumentacją warto się zapoznać albo u jakiego specjalisty szukać wsparcia.
W kolejnym kroku do optymalizacji SEO wykorzystamy X-Robots-Tag.
Dyrektywa X-Robots-Tag jest dyrektywną indeksatora. Stanowi odpowiedź nagłówka HTTP. Dyrektywa dodawana jest z poziomu serwera na przykład poprzez plik .htaccess, jeżeli będzie to serwer typu Apatche. X-Robots-Tag jest ustawiany na podstawie strony/elementu bądź wspólnego parametru w adresie URL. Dyrektywa przekazuje nofollow oraz noindex z poziomu nagłówka HTTP, więc nie będzie ona widoczna w plikach źródłowych strony.
W zależności o typu serwera, dyrektywa może być deklarowana w różny sposób. Poniżej znajdują się dwie podstawowe metody oparte o plik .htaccess oraz PHP:
PHP – poniższy kod dodajemy do pliku header.php. Poniższy kod działa globalnie, więc jeżeli chcemy zastosować go do określonych podstron to należy dopisać warunkowanie w języku php:
header(„X-Robots-Tag: noindex, nofollow”, true);
.htaccess – bardziej praktyczne i szybsze rozwiązanie to dodanie kilku komend do pliku .htaccess. Poniżej kody, które usprawnią nam optymalizację budżetu indeksowania:
– Blokowanie indeksacji plików typu doc,pdf,xls
<FilesMatch „.doc$”>
Header set X-Robots-Tag „noindex, noarchive, nosnippet”
</FilesMatch>
– Blokowanie adresów URL z parametrami
RewriteCond %{QUERY_STRING} (?dir=|?order=|?sort=|?limit=|?query=|?q=)
RewriteRule .* – [E=NOINDEX_HEADER:1]
Header set X-Robots-Tag „noindex, nofollow” env=REDIRECT_NOINDEX_HEADER
– Kanonikalizacja adresów URL
RewriteRule ([^/]+).pdf$ – [E=FILENAME:$1]
<FilesMatch „.pdf$”>
Header add Link '<http://www.example.com/download/%{FILENAME}e>; rel=”canonical”’
</FilesMatch>
Jeżeli chcemy zweryfikować poprawność wdrożenia bądź nie możemy w kodzie strony znaleźć meta tagów blokujących, pomimo że dana podstrona jest wykluczona, to warto skorzystać z jednego z dwóch poniższych narzędzi:
Pierwszy sposób to skorzystanie z wtyczki go przeglądarki Google Chrome znajdującej się pod tym linkiem:
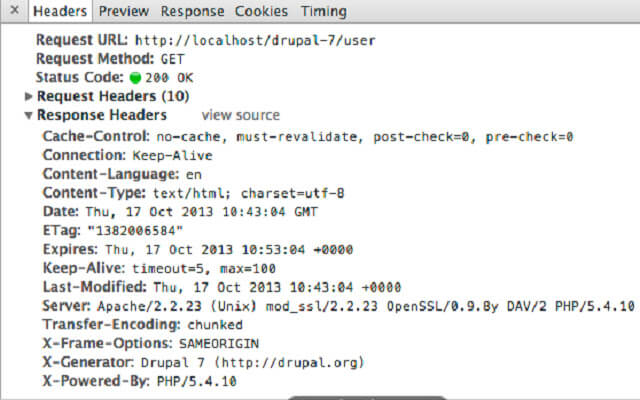
Drugi to wykorzystanie narzędzi online takich jak na przykład https://websniffer.cc

Korzystanie z dyrektyw nagłówka HTTPS to idealne rozwiązanie, jeżeli mamy problem z osadzeniem noindex,nofollow dla adresów URL, które generowane są dynamicznie bądź mamy ograniczony dostęp do plików źródłowych. Wykluczanie zasobów z indeksacji jest istotne pod kątem optymalizacji budżetu indeksowania.


Grzegorz
Maliszewski
HEAD OF BUSINESS DEVELOPMENT
tel. +48 577 997 701
e-mail wspolpraca@promotraffic.pl
PromoTraffic to przede wszystkim wysoki standard obsługi.
Jest to agencja, która podchodzi do zagadnienia marketingu w sposób kompleksowy.
Adam Grybalow
4FIZJO

Z przyjemnością rekomendujemy Agencję PromoTraffic jako rzetelnego i kreatywnego partnera, z którym mamy okazję współpracujemy w obszarach digital marketingu.
Milena Zielińska
VanityStyle

Ponad 13 lat doświadczenia, nieustanny #PROgress i sukcesy naszych Klientów.











